SFT, RL, and On-Policy Distillation Through a Distributional Lens
On forgetting, generalization, and what connects RL to on-policy distillation

I have been thinking about post-training methods in terms of distributions. A language model is a distribution over sequences. When we post-train it and attempt to teach it a task, we are reshaping this distribution. Different post-training methods differ in how they reshape this distribution, what they treat as the target and how directly they define this target.
This is neither a very precise statement nor is it meant to be fully rigorous. I just find it to be a useful mental model, but I think it explains a lot of the qualitative differences between SFT, RL, and On-Policy Distillation. This is the intuition I want to explore in this post.
A Distributional View of Post-Training
Under this view, the most important question to ask is: What is the target distribution that we are optimizing towards?
SFT: A Fixed External Target Distribution.
SFT is the simplest case.
You have an annotated dataset. Maybe it was written by humans. Maybe it was generated by a stronger model. Either way, the dataset exists before training. Then you do cross-entropy training on your starting model. In distribution terms, the current model is one distribution, and the dataset defines another distribution. SFT pulls the model toward the dataset distribution.
Because of the nature of negative log likelihood, the distribution that you start with does not actually matter. This is why I think SFT has a very natural Catastrophic Forgetting failure mode. If the dataset distribution is far from the model’s original distribution, the model has no built-in reason to prefer a nearby solution and is simply pulled toward the demonstrated tokens.
This does not mean SFT is bad. SFT is incredibly useful. But in terms of geometry, it is a very direct pull toward an external target with little regard for the starting policy. This makes it good for “cold-start” type tasks where the expected output format needs to be changed drastically.

RL: Direction of Greatest Expected Reward
Online Reinforcement Learning (RL) looks different. The model generates samples from itself; these samples are scored by some reward function; then the model is updated to increase the expected reward it receives via Policy Gradient.
Here, the concept of a “target distribution” is a lot harder to define. I will revisit this in later sections but at a high level, there isn’t an arbitrary external distribution that the model is being pulled towards.

Of course, this only works if the reward is meaningful. In RLVR, where the reward is verifiable, the reward direction is often a pretty good proxy for quality and so moving along the reward direction should get us a better model. In RLHF, where the reward model is imperfect, the situation is messier. We will come back to this later.
On-Policy Distillation: Pseudo RL
On-policy distillation (OPD) is somewhere between SFT and RL. Like SFT, it has a teacher signal. The student is trained to match another distribution but like RL, the data comes from the student. At each step, the algorithm is performing on-policy sampling but the gradient is pulling the model towards matching the teacher’s distribution via reverse KL divergence. Loosely, OPD can be thought of as similar in nature to RL where instead of weighting completions by advantage, it weights using the log ratio between the student and the teacher.
A new variant of OPD is On-Policy Self Distillation (OPSD) . The teacher and student are the same model but when computing the ’teacher’ log probabilities, the teacher is provided with the reference solution as a prefix. The idea being this privileged information that the teacher has access to will provide the learning signal.
The problem with this is that since the student and teacher model are the same model, they end up having very similar outputs for most tokens. The authors did a per-token KL analysis and found that style or pivot tokens, things like “wait” or “alright”, could have higher KL than math tokens like “power”, “exponent”, or “logarithm”. Therefore, if we update too aggressively on these unimportant tokens, the model might collapse. The solution is thus to introduce a per-token clipping mechanism to prevent over updates.
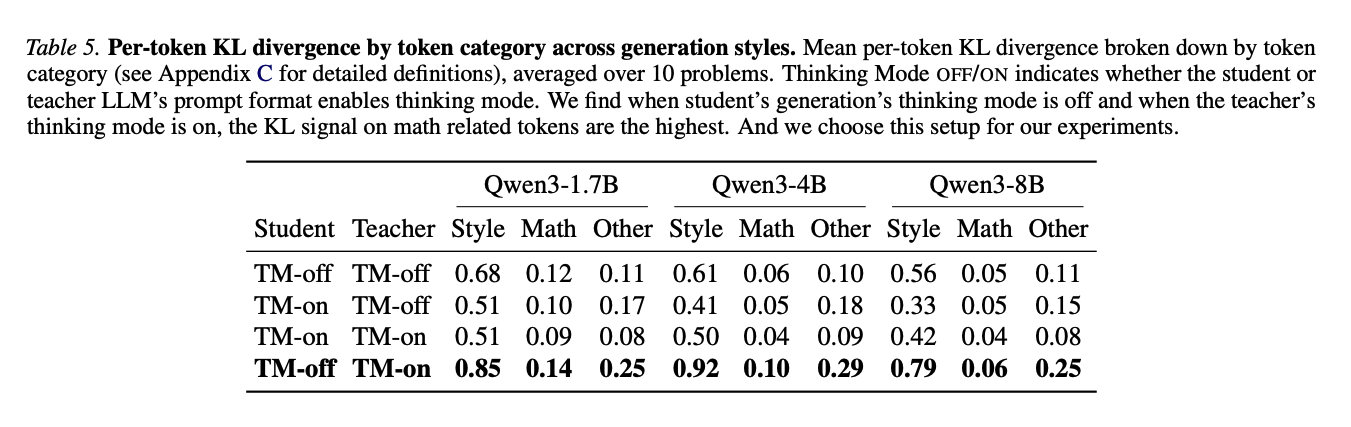
This is why OPSD feels closer to RLHF than RLVR. In RLHF, the signal from the reward model has higher bias, so we use KL penalties and trust-region style clipping to avoid over-optimizing the wrong thing. In OPSD, the teacher signal is also not perfectly correlated with task importance since some high KL tokens could simply be style. With verifiable rewards, the reward function is lower bias. This is why (among other reasons) people are often more comfortable removing explicit KL penalties or loosening trust-region constraints (using GRPO instead of PPO) in RLVR.
A common argument is that RLVR with outcome rewards struggles with per-token credit-assignment and the advantage function provides only O(1) bits of information per episode (Schulman et al., 2025 ). OPSD seems to be on the opposite extreme where each token gets its unique ‘reward’ but the algorithm introduces more noise and bias per update.
On-Policy Distillation With Different Teachers
The setup for this experiment uses my Minimal Code Editing task. I highly encourage reading my previous post to get some context before continuing here. As a quick summary, the model is provided with a buggy corrupted function and asked to fix the bug and nothing else. We check if the model’s solution works and if any other part of the function has been rewritten against the original uncorrupted function. I like this environment because it helps test for 2 things:
- Generalization: I can train the model on one set of corruption types, then evaluate it on a different set of corruptions. This lets me ask whether the model learned the general behavior of minimum editing, or whether it only learned to reverse specific corruptions.
- Catastrophic Forgetting: Unlike standard code generation tasks, minimum editing is a niche coding behavior. I can thus evaluate the fine-tuned model on LiveCodeBench to check for any degradation in code generation ability.
For this experiment, I first trained two teacher models with SFT and RL respectively. The performance of both teachers replicated the results in the previous post. Both learned the minimum editing behavior but RL generalized better and did not show meaningful forgetting while SFT showed degradation on general code generation. Before performing OPD, I expected the student distilled from the RL teacher to perform better.
| Model | Pass@1 ↑ | Norm. Levenshtein ↓ | Added CC ↓ | LiveCodeBench v6 ↑ |
|---|---|---|---|---|
| Teachers | ||||
| SFT | 0.775 | 0.450 | 0.450 | 0.286 |
| RL | 0.792 | 0.063 | 0.206 | 0.320 |
| Students (OPD) | ||||
| OPD SFT teacher | 0.800 | 0.059 | 0.206 | 0.297 |
| OPD RL teacher | 0.787 | 0.055 | 0.228 | 0.314 |
This is not what happened.
The OPD student trained from the SFT teacher and the OPD student trained from the RL teacher ended up looking extremely similar. Even more surprisingly, both OPD students slightly outperformed the RL teacher and significantly outperformed the SFT teacher. This was true even though the RL teacher had a higher final reward during its own training run.
Further, even though the SFT teacher showed degradation on general code generation and the RL teacher did not, the OPD students trained from both teachers showed only slight forgetting. The OPD student forgot less than the SFT teacher, even when the teacher itself was the degraded SFT model. This was really surprising since if the teacher distribution were the main thing that mattered, then the student trained from the SFT teacher should inherit more of the SFT teacher’s forgetting. But it did not.
This suggests that the source of the data (ie. via on-policy sampling) matters a lot while the teacher matters perhaps less than I expected. This is a hopeful result because it means that we can “overtrain” a specialized model - maybe even via brute-force SFT - and then do OPD to learn this capability while preserving a lot of the other capabilities we care about.
Why Does RL Forget Less?
There are a few common explanations and while I think all of them contain some truth, I do not find most fully satisfying.
SFT is Forward KL, RL is Reverse KL
The first explanation is often related to the directions of KL divergence both algorithms are optimizing for. SFT via Cross Entropy on a fixed dataset is equivalent to minimizing forward KL divergence, up to constants.
$$ \begin{align} D_{KL}(p \| q_\theta) &= \sum_x p(x) \log \frac{p(x)}{q_\theta(x)} \\ &= \sum_x p(x) \log p(x) - \sum_x p(x) \log q_\theta(x) \\ &= -H(p) + H(p, q_\theta) \end{align} $$The mode-covering behavior of forward KL could thus lead to sacrificing previous modes (representing pre-existing capabilities) to learn the new task. Chen et al., 2025 showed that RL can be thought of as reverse KL minimization.
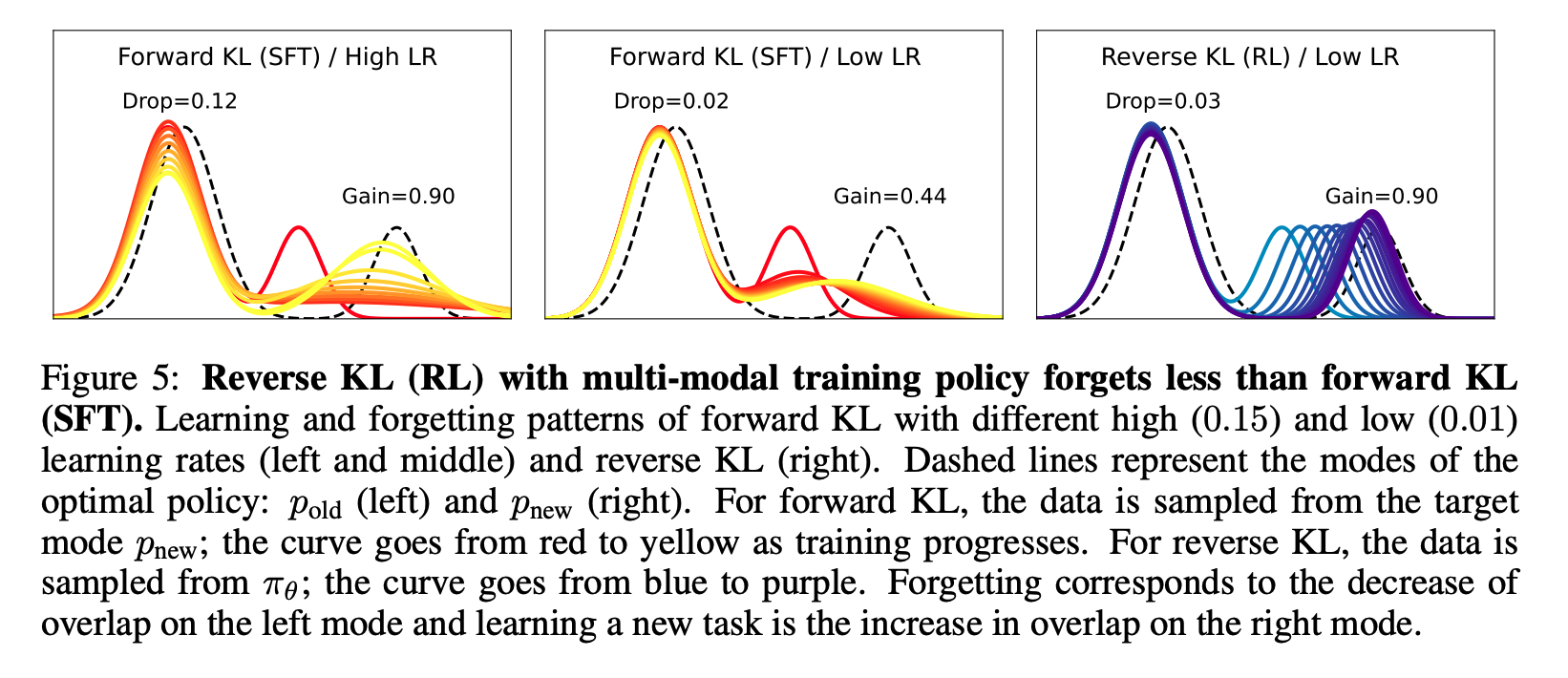
I find such arguments to be useful but incomplete. The problem is that the argument leans heavily on explicit KL regularization against a reference model. But empirically, RL can still be resistant to forgetting even when this KL penalty is removed or heavily reduced. In RLVR, people often train with much weaker KL constraints than in RLHF-style setups, and yet the anti-forgetting behavior often remains.
SFT Has Uniform, Aggressive Token-Level Gradients
Data dependent regularization
First, SFT gives dense, uniform supervision on every token. In SFT, every demonstrated token is treated as something the model should increase probability on. The token could be task-critical, like a mathematical operator, or it could be a style token, like “therefore” or “we can see that”. The loss does not know the difference and it just pushes up the probability of the demonstrated token, creating broad updates. Diao et al. found that SFT contains many tokens with low probability and low entropy. This means that the model is highly confident in its prediction but is forced to fit a divergent ground-truth label which would impact existing representations.
In contrast, RL has some form of data-dependent regularization (Lai et al., 2025 ). For example during advantage estimation when rewards are normalized within a group, a group with higher diversity and reward variance receives smaller updates compared to a group with low variance. This means that when the model is uncertain, the update magnitude is naturally reduced. Conversely, for samples where the model produces consistently high-reward responses, the update is more aggressive.
RL has sparser parameter updates
As a result, Mukherjee et al. found that RL updates only a small subnetwork of a model via sparse but full-rank updates while SFT induces dense ones. Similarly, Yuan et al. found that SFT has more redundancy in parameter updating. When they prune the number of parameters updated of both SFT and RL, they found that the performance of RL degrades much faster, confirming that SFT updates are more redundant, while RL updates are more important to the final task performance
While both parts of the argument are empirically sound when it comes to the SFT vs RL comparison, I slightly question if they are general enough to be applied to algorithm-analysis or are the results just specific to the domains the authors tested. Further, how does OPD fit into this picture?
The Explanation I Prefer: On-Policy Data
The explanation I most align with is the one from Shenfeld et al. . I encourage interested readers to read the original paper but the intuition is easiest to see with a very simple version of RL. Suppose we use REINFORCE with a binary 0/1 reward. Then, if the reward is 1, it contributes positive training signal. If the reward is 0, it contributes none. In that case, reward is acting like a filter and it looks very similar to rejection sampling.
If we go back to the initial idea of a target distribution, RL now has one. We can define an optimal policy as the policy where all completions under said policy have reward of 1. Of course, there are multiple optimal policies but because we are training on on-policy samples generated by the current policy, this optimal distribution is the closest among all optimal policies to our current policy. When we perform a policy gradient update step, we are trying to fit our current policy to this new optimal policy which implicitly has low KL to our current policy. Therefore, RL learns the nearest task-solving policy.
This gives us a very different geometrical view to think about forgetting. On-policy data constrains the training procedure towards a distribution close to the starting policy at every time step. In contrast, the target distribution for SFT could be arbitrarily far away.
This is why I think OPD inherits some of RL’s anti-forgetting behavior and why the OPD student distilled from the SFT teacher can forget less than the SFT teacher itself. The teacher was trained on external data while the student is trained on its own data. Even though the teacher provides the signal, the state distribution is still the student’s.
This also answers why on-policy distillation may be more robust to forgetting behavior. Admittedly, the signal from on-policy distillation could be higher variance because the logits distribution is not perfect, but because of the on-policy nature, it has implicit KL regularization built into the setup.

Why Can the Student Outperform the Teacher?
This is another surprising part of the experiment but it is not new. In fact, in the original work by Agarwal et al. , they show that distilled students surpass the teacher’s performance on GSM8K. I do not have a concrete explanation but I think there are a few plausible hypotheses.
Unlike in traditional distillation, OPD’s supervision could be more targeted as it uses student-generated states. This matters because the student’s mistakes are not necessarily the teacher’s mistakes. If we train only on teacher-generated trajectories, the student may receive supervision on parts of the distribution it rarely visits. But in OPD, the teacher gives advice on the student’s own prefixes.
Second, KL matching is not the same as reward maximization. At the start of this post, I described OPD as somewhat analogous to RL with token-level teacher supervision but this analogy is imperfect. The training signal from minimizing KL has significantly higher bias than standard RLVR rewards. The teacher distribution may contain information about style, uncertainty, alternative continuations, and reasoning structure. Matching it can reshape the student distribution in ways that improve sampling behavior without exactly reproducing the teacher’s greedy behavior.
So the student can improve even if the teacher’s own sampled outputs are not better. This is hard to reason about if we only think in terms of individual tokens. It makes more sense if we think in terms of distributional shaping.
This perspective of thinking about training as changing the shape of the model distribution can be unintuitive. One example is this work by Zhang et al.. The authors report coding improvements when trained on a dataset consisting of 1 model-generated completion per prompt with no correctness filtering. Even more surprising is that when they self-distill using high temperature - resulting in gibberish training data, training on this poor quality data still improves performance. The authors attempt to explain the results by comparing probability outputs at certain tokens but the point is that it is extremely challenging for one to build intuition around these high dimensional things.
My best attempt at an explanation here is that the model is experiencing mode collapse around the new capability. Looking at entropy statistics during OPD and RL, the entropy collapse is significantly more drastic with OPD. This is to be expected with the mode-seeking behavior of reverse KL training where mode-collapse might lead to decreased diversity (Gu et al., 2023 ). I do not want to overstate this since this section is speculative but I do think the distributional view is the right place to start.

Why Do RL and OPD Generalize Better?
Much of what explains this follows from the analysis in the sections above. Firstly, in SFT, the model is penalized for not assigning probability to a specific answer. On the other hand, RL is less imitation-like by construction since the supervision is attached to task success rather than a specific sequence of tokens.
Crucially, we can borrow the work of Ross et al. . In SFT, the model only sees states the teacher visits. At test time because of autoregression, one mistake by the student might move it to states the teacher would have never visited. This mismatch can result in compounding errors when the student’s prefix (or current state) differs from what the teacher would have done. As such, on-policy data aggregation can reduce this mismatch.
The Full Pipeline
Most (open) models use a Pretrain-SFT-RL-OPD pipeline. SFT is required after pretraining for both format adherence and to instill basic instruction following capability, without which it would be impossible to perform RL efficiently (Chu et al., 2025 ). But what happens after?
Recently, both GLM 5 and DeepSeek v4 use OPD to merge expert capabilities into the final model with the final checkpoint never going through RL. This begs the following question: how should we train these experts? A useful reference point to compare across methods is the MiMo-V2 Flash technical report .
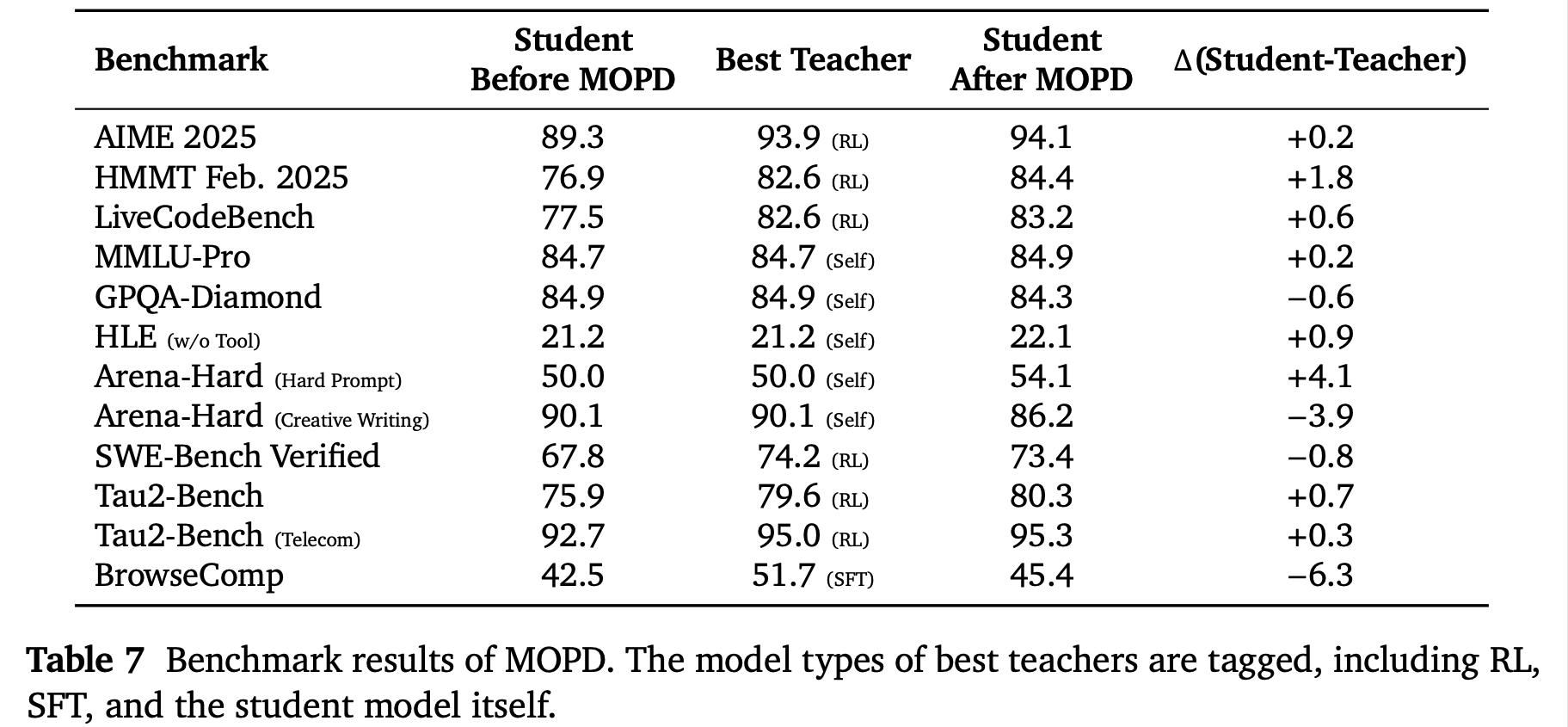
Math and Code tasks tend to favor RL. This is not surprising, we know RLVR works on these domains. Creative writing and some knowledge-heavy benchmarks seem to benefit more from self-distillation or distillation-style methods. This also makes sense since in these domains, reward is much noisier. If we rely on an LLM judge, we are optimizing a biased proxy for quality.
The table also compares the performance of the final merged model against each teacher. The only domains where the student is actually worse off than the teacher are domains where the teacher is self-distilled as well as BrowseComp from the SFT domain. In the RL domain, the final merged model almost always outperforms the teacher to varying degrees of success. It remains to be seen why that is the case, but I thought it was interesting to point out nonetheless given the convergence towards some form of expert merging being the final stage of most post-training pipelines.
The Best Algorithm
This post was inspired by Brown, 2026 , which frames each post-training method as maximizing capability under a different tradeoff against KL to a prior. The article ends by suggesting the existence of some algorithm more compute-optimal than RL that still preserves the Pareto frontier of capability versus KL movement.
What I hope to have convinced you of in this post is that any such algorithm will have to lean on on-policy data. It isn’t that RL is a uniquely special algorithm, and it isn’t that explicit KL penalties are doing the heavy lifting. The thing that lets you push capability up without blowing through your KL budget is on-policy training. The insight isn’t new (Lu et al., 2025 ), but I haven’t found a single place that pulls the research together, and most of the literature still treats RL as flatly ‘superior’.
The growing popularity of On-Policy Distillation has actually made this easier to see. Putting it next to RL and SFT, the fact that OPD and RL end up in similar places is what convinces me that on-policy data is the load-bearing ingredient. The other knob, and the one I think this hypothetical algorithm has to get right, is the old credit assignment problem. Outcome rewards are too sparse, which is why RL is so expensive. Process Reward Models in the style of Lightman et al. don’t train efficiently at scale. Logit distillation from a teacher gives a denser signal per token but at the cost of bias, which then forces you into messy clipping schemes.
So the shape of the problem is clearer than the solution: you want something with the density of distillation, the unbiasedness of RL, and the on-policy property of both. What that actually looks like as a concrete algorithm, I don’t know.